通过使用zabbix 日志监控 我发现一个问题 例如oracle的日志有报错的情况 ,通常不会去手动清理 这样的话当第二次有日志写进来的时候 zabbix的机制是回去检查全部日志,这样的话之前已经告警过的错误日志,又会被检查到,这样就会出现重复告警,而且zabbix的日志监控只能读到匹配当前行关键字的数据,感觉不太灵活, 比如我想要匹配到的关键字之后再当前关键字的下N行再去匹配另一个关键字这个时候就比较麻烦,在这里给大家推荐一个有效,便捷解决的方式。
通过Python脚本实现日志监控 要求 1 记录脚本检查日志位置,避免下次触发脚本的时候出现重复告警 2 关键字匹配支持正则 3 支持多个关键字查询,例如第一个关键字匹配到当之后在这个关键字的下N行再去匹配第二个关键字 具体传参格式
python3 npar.py /u03/z.txt '(ORA-|REEOR),(04030|02011)' 2
第一个参数是日志路径 第二个参数是关键字 第三个参数为 匹配到第一个表达式这种的关键字后再去地 N(2)行去匹配第二个关键词(04030|02011)具体脚本实现如下
import os
import sys
logtxt = "logtxt.txt"
def read_txt(files, start_line):
data = []
data.append("")
with open(str(files) + "", "r",
encoding = 'UTF-8') as f:
for line in f.readlines():
line = line.strip('\n')# 去掉列表中每一个元素的换行符
data.append(line)
# 记录本次的行数
wirte_log(len(data) - 1)
if len(data) > start_line:
return data[start_line - 1: ]
else :
print("开始行数大于文本文件总行数!")
def wirte_log(lines):
global logtxt
with open(logtxt, "w") as file: #”w "代表着每次运行都覆盖内容
file.write(str(lines))
def read_log():
global logtxt
if not os.path.exists(logtxt):
with open(logtxt, "w") as file: #”w "代表着每次运行都覆盖内容
file.write(str(1))
with open(logtxt + "", "r", encoding =
'UTF-8') as f:
s_lines = f.readlines()
print("从第" + str(s_lines[0]) + "行开始")
return s_lines[0]
def deal_read_log(files, keyword,
interval_line):
keywords = keyword.replace("(", "").replace(
")", "").replace("'", "").replace('"',
'"').split(',')
start_keywords = keywords[0].split("|")
end_keywords = keywords[1].split("|")
start_line = read_log()
lines_data = read_txt(files, int(
start_line))
for_line = 1
while (for_line < len(lines_data)):
#print(for_line)
# print(lines_data[for_line])
#
if end_keywords in lines_data[for_line]:
#print(lines_data[for_line])
# print("-------------------")
# for_line = for_line + 1
#
else :
isexist = 0
for sk in start_keywords:
if sk in lines_data[for_line]:
isexist = 1
break;
if isexist == 1:
#if start_keywords[0] in lines_data[
for_line] or start_keywords[1] in
lines_data[for_line]:
#当前行有end_keywords
isexist2 = 0
for sk in end_keywords:
if sk in lines_data[for_line]:
isexist2 = 1
break;
if isexist2 == 1:
#print("行数=" + str(start_line - 1 +
for_line) + "-" + str(start_line - 1 +
for_line))
print(lines_data[for_line])
else :
#当前行没有end_keywords。 往下interval_line行去寻找
# 标记当前行数
flag_line = for_line
count = 1
for_line = for_line + 1
while (for_line < len(lines_data)):
isexist3 = 0
for sk in end_keywords:
if sk in lines_data[for_line]:
isexist3 = 1
break;
if isexist3 == 1:
#print("行数=" + str(start_line - 1 +
flag_line) + "-" + str(start_line -
1 + for_line))
for prin in range(flag_line, for_line +
1):
print(lines_data[prin])
break;
for_line = for_line + 1
if count == int(interval_line):
break;
count = count + 1
for_line = for_line - 1
for_line = for_line + 1
if name == 'main':
files = sys.argv[1]
if '.log' in files:
logtxt = files.replace(".log",
"_log.txt")
else :
logtxt = files.replace(".txt",
"_log.txt")
# files = "ora.txt"
keywords = sys.argv[2]
# keywords = "'((04030|04000),ORA-)'"
#上下关联行数
interval_line = int(sys.argv[3])
# interval_line = 10
deal_read_log(files, keywords,
interval_line)
接下来就是添加监控了
在agent的conf 文件里面添加UserParameter

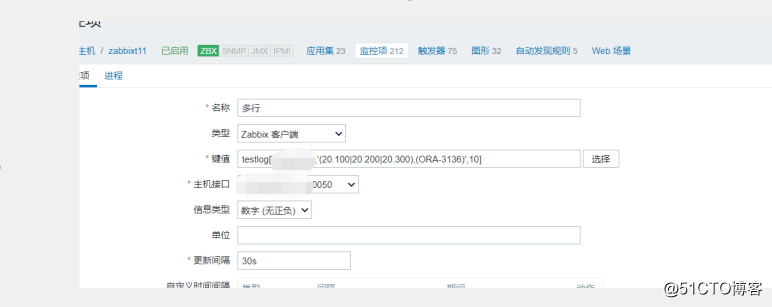
到这里监控就完成了
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持。
免责声明:本站资源来自互联网收集,仅供用于学习和交流,请遵循相关法律法规,本站一切资源不代表本站立场,如有侵权、后门、不妥请联系本站删除!
《魔兽世界》大逃杀!60人新游玩模式《强袭风暴》3月21日上线
暴雪近日发布了《魔兽世界》10.2.6 更新内容,新游玩模式《强袭风暴》即将于3月21 日在亚服上线,届时玩家将前往阿拉希高地展开一场 60 人大逃杀对战。
艾泽拉斯的冒险者已经征服了艾泽拉斯的大地及遥远的彼岸。他们在对抗世界上最致命的敌人时展现出过人的手腕,并且成功阻止终结宇宙等级的威胁。当他们在为即将于《魔兽世界》资料片《地心之战》中来袭的萨拉塔斯势力做战斗准备时,他们还需要在熟悉的阿拉希高地面对一个全新的敌人──那就是彼此。在《巨龙崛起》10.2.6 更新的《强袭风暴》中,玩家将会进入一个全新的海盗主题大逃杀式限时活动,其中包含极高的风险和史诗级的奖励。
《强袭风暴》不是普通的战场,作为一个独立于主游戏之外的活动,玩家可以用大逃杀的风格来体验《魔兽世界》,不分职业、不分装备(除了你在赛局中捡到的),光是技巧和战略的强弱之分就能决定出谁才是能坚持到最后的赢家。本次活动将会开放单人和双人模式,玩家在加入海盗主题的预赛大厅区域前,可以从强袭风暴角色画面新增好友。游玩游戏将可以累计名望轨迹,《巨龙崛起》和《魔兽世界:巫妖王之怒 经典版》的玩家都可以获得奖励。
更新日志
- 凤飞飞《我们的主题曲》飞跃制作[正版原抓WAV+CUE]
- 刘嘉亮《亮情歌2》[WAV+CUE][1G]
- 红馆40·谭咏麟《歌者恋歌浓情30年演唱会》3CD[低速原抓WAV+CUE][1.8G]
- 刘纬武《睡眠宝宝竖琴童谣 吉卜力工作室 白噪音安抚》[320K/MP3][193.25MB]
- 【轻音乐】曼托凡尼乐团《精选辑》2CD.1998[FLAC+CUE整轨]
- 邝美云《心中有爱》1989年香港DMIJP版1MTO东芝首版[WAV+CUE]
- 群星《情叹-发烧女声DSD》天籁女声发烧碟[WAV+CUE]
- 刘纬武《睡眠宝宝竖琴童谣 吉卜力工作室 白噪音安抚》[FLAC/分轨][748.03MB]
- 理想混蛋《Origin Sessions》[320K/MP3][37.47MB]
- 公馆青少年《我其实一点都不酷》[320K/MP3][78.78MB]
- 群星《情叹-发烧男声DSD》最值得珍藏的完美男声[WAV+CUE]
- 群星《国韵飘香·贵妃醉酒HQCD黑胶王》2CD[WAV]
- 卫兰《DAUGHTER》【低速原抓WAV+CUE】
- 公馆青少年《我其实一点都不酷》[FLAC/分轨][398.22MB]
- ZWEI《迟暮的花 (Explicit)》[320K/MP3][57.16MB]