基本环境配置
- python 3.6
- pycharm
- requests
- parsel
相关模块pip安装即可
目标网页

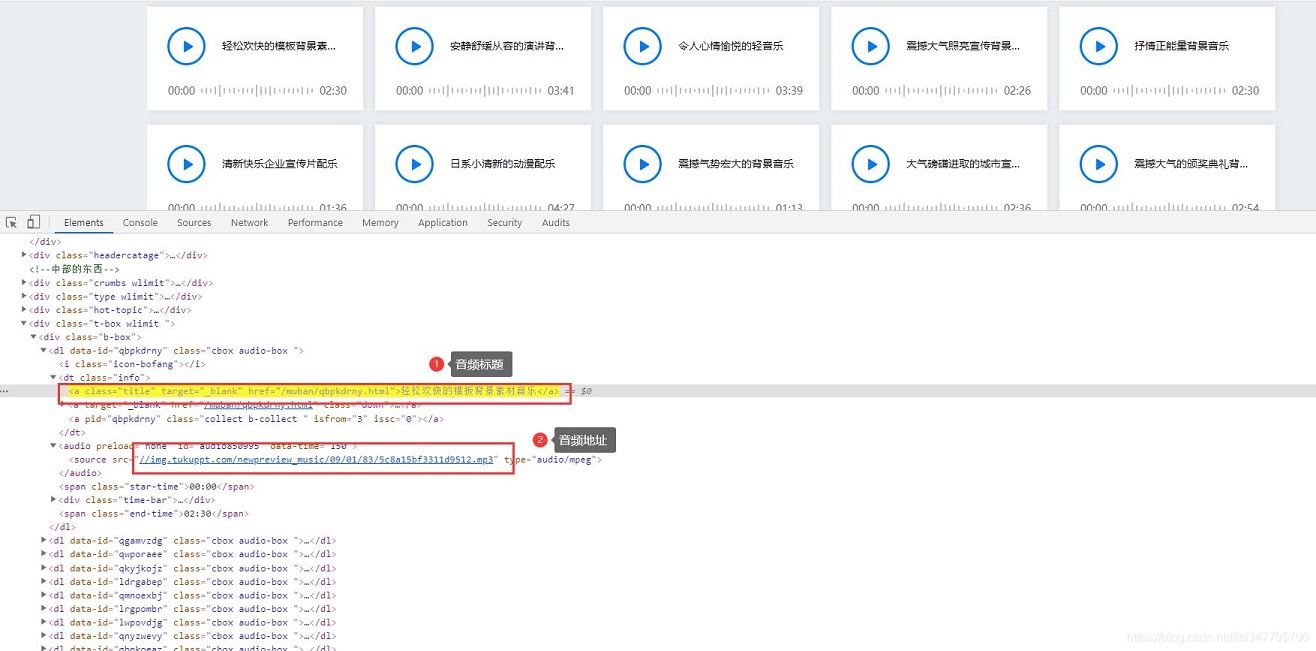
请求网页
import requests
url = 'https://www.tukuppt.com/peiyue/zonghe_0_0_0_0_0_0_1.html'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36',
}
response = requests.get(url=url, headers=headers)
解析网页,提取数据
import parsel
selector = parsel.Selector(response.text)
urls = selector.css('#audio850995 source::attr(src)').getall()
titles = selector.css('.b-box .info .title::text').getall()
data = zip(urls, titles)
for i in data:
mp3_url = 'https:' + i[0]
title = i[1]
保存数据
def download(url, title):
response = requests.get(url=url, headers=headers)
path = 'D:\\python\\demo\\熊猫办公素材\\背景音乐\\' + title + '.mp3'
with open(path, mode='wb') as f:
f.write(response.content)


以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持。
广告合作:本站广告合作请联系QQ:858582 申请时备注:广告合作(否则不回)
免责声明:本站资源来自互联网收集,仅供用于学习和交流,请遵循相关法律法规,本站一切资源不代表本站立场,如有侵权、后门、不妥请联系本站删除!
免责声明:本站资源来自互联网收集,仅供用于学习和交流,请遵循相关法律法规,本站一切资源不代表本站立场,如有侵权、后门、不妥请联系本站删除!
暂无评论...
更新日志
2024年12月25日
2024年12月25日
- 小骆驼-《草原狼2(蓝光CD)》[原抓WAV+CUE]
- 群星《欢迎来到我身边 电影原声专辑》[320K/MP3][105.02MB]
- 群星《欢迎来到我身边 电影原声专辑》[FLAC/分轨][480.9MB]
- 雷婷《梦里蓝天HQⅡ》 2023头版限量编号低速原抓[WAV+CUE][463M]
- 群星《2024好听新歌42》AI调整音效【WAV分轨】
- 王思雨-《思念陪着鸿雁飞》WAV
- 王思雨《喜马拉雅HQ》头版限量编号[WAV+CUE]
- 李健《无时无刻》[WAV+CUE][590M]
- 陈奕迅《酝酿》[WAV分轨][502M]
- 卓依婷《化蝶》2CD[WAV+CUE][1.1G]
- 群星《吉他王(黑胶CD)》[WAV+CUE]
- 齐秦《穿乐(穿越)》[WAV+CUE]
- 发烧珍品《数位CD音响测试-动向效果(九)》【WAV+CUE】
- 邝美云《邝美云精装歌集》[DSF][1.6G]
- 吕方《爱一回伤一回》[WAV+CUE][454M]