前言
tensorflow提供了多种读写方式,我们最常见的就是使用tf.placeholder()这种方法,使用这个方法需要我们提前处理好数据格式,不过这种处理方法也有缺陷:不便于存储和不利于分布式处理,因此,TensorFlow提供了一个标准的读写格式和存储协议,不仅如此,TensorFlow也提供了基于多线程队列的读取方式,高效而简洁,读取速度也更快,据一个博主说速度能提高10倍,相当的诱人.【下面的实验均是在tensorflow1.0的环境下进行】
tensorflow的example解析
example协议
在TensorFlow官方github文档里面,有个example.proto的文件,这个文件详细说明了TensorFlow里面的example协议,下面我将简要叙述一下。
tensorflow的example包含的是基于key-value对的存储方法,其中key是一个字符串,其映射到的是feature信息,feature包含三种类型:
BytesList:字符串列表
FloatList:浮点数列表
Int64List:64位整数列表
以上三种类型都是列表类型,意味着都能够进行拓展,但是也是因为这种弹性格式,所以在解析的时候,需要制定解析参数,这个稍后会讲。
在TensorFlow中,example是按照行读的,这个需要时刻记住,比如存储  矩阵,使用ByteList存储的话,需要
矩阵,使用ByteList存储的话,需要 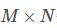 大小的列表,按照每一行的读取方式存放。
大小的列表,按照每一行的读取方式存放。
tf.tain.example
官方给了一个example的例子:
An Example for a movie recommendation application:
features {
feature {
key: "age"
value { float_list {
value: 29.0
}}
}
feature {
key: "movie"
value { bytes_list {
value: "The Shawshank Redemption"
value: "Fight Club"
}}
}
feature {
key: "movie_ratings"
value { float_list {
value: 9.0
value: 9.7
}}
}
feature {
key: "suggestion"
value { bytes_list {
value: "Inception"
}}
}
上面的例子中包含一个features,features里面包含一些feature,和之前说的一样,每个feature都是由键值对组成的,其key是一个字符串,其value是上面提到的三种类型之一。
Example中有几个一致性规则需要注意:
如果一个example的feature K 的数据类型是 TT,那么所有其他的所有feature K都应该是这个数据类型
feature K 的value list的item个数可能在不同的example中是不一样多的,这个取决于你的需求
如果在一个example中没有feature k,那么如果在解析的时候指定一个默认值的话,那么将会返回一个默认值
如果一个feature k 不包含任何的value值,那么将会返回一个空的tensor而不是默认值
tf.train.SequenceExample
sequence_example表示的是一个或者多个sequences,同时还包括上下文context,其中,context表示的是feature_lists的总体特征,如数据集的长度等,feature_list包含一个key,一个value,value表示的是features集合(feature_lists),同样,官方源码也给出了sequence_example的例子:
//ontext: {
feature: {
key : "locale"
value: {
bytes_list: {
value: [ "pt_BR" ]
}
}
}
feature: {
key : "age"
value: {
float_list: {
value: [ 19.0 ]
}
}
}
feature: {
key : "favorites"
value: {
bytes_list: {
value: [ "Majesty Rose", "Savannah Outen", "One Direction" ]
}
}
}
}
feature_lists: {
feature_list: {
key : "movie_ratings"
value: {
feature: {
float_list: {
value: [ 4.5 ]
}
}
feature: {
float_list: {
value: [ 5.0 ]
}
}
}
}
feature_list: {
key : "movie_names"
value: {
feature: {
bytes_list: {
value: [ "The Shawshank Redemption" ]
}
}
feature: {
bytes_list: {
value: [ "Fight Club" ]
}
}
}
}
feature_list: {
key : "actors"
value: {
feature: {
bytes_list: {
value: [ "Tim Robbins", "Morgan Freeman" ]
}
}
feature: {
bytes_list: {
value: [ "Brad Pitt", "Edward Norton", "Helena Bonham Carter" ]
}
}
}
}
}
一致性的sequence_example遵循以下规则:
1、context中,所有feature k要保持数据类型一致性
2、一些example中的某些feature_lists L可能会丢失,如果在解析的时候允许为空的话,那么在解析的时候回返回一个空的list
3、feature_lists可能是空的
4、如果一个feature_list是非空的,那么其里面的所有feature都必须是一个数据类型
5、如果一个feature_list是非空的,那么对于里面的feature的长度是不是需要一样的,这个取决于解析时候的参数
tensorflow 的parse example解析
在官方代码*[parsing_ops.py]*中有关于parse example的详细介绍,我在这里再叙述一下。
tf.parse_example
来看tf.parse_example的方法定义:
def parse_example(serialized, features, name=None, example_names=None)
parse_example是把example解析为词典型的tensor
参数含义:
serialized:一个batch的序列化的example
features:解析example的规则
name:当前操作的名字
example_name:当前解析example的proto名称
这里重点要说的是第二个参数,也就是features,features是把serialized的example中按照键值映射到三种tensor: 1,VarlenFeature 2, SparseFeature 3,FixedLenFeature
下面对这三种映射方式做一个简要的叙述:
VarlenFeature
是按照键值把example的value映射到SpareTensor对象,假设我们有如下的serialized数据:
serialized = [
features
{ feature { key: "ft" value { float_list { value: [1.0, 2.0] } } } },
features
{ feature []},
features
{ feature { key: "ft" value { float_list { value: [3.0] } } }
]
使用VarLenFeatures方法:
features={
"ft":tf.VarLenFeature(tf.float32)
}
那么我们将得到的是:
{"ft": SparseTensor(indices=[[0, 0], [0, 1], [2, 0]],
values=[1.0, 2.0, 3.0],
dense_shape=(3, 2)) }
可见,显示的indices是ft值的索引,values是值,dense_shape是indices的shape
FixedLenFeature
而FixedLenFeature是按照键值对将features映射到大小为[serilized.size(),df.shape]的矩阵,这里的FixLenFeature指的是每个键值对应的feature的size是一样的。对于上面的例子,如果使用:
features: {
"ft": FixedLenFeature([2], dtype=tf.float32, default_value=-1),
}
那么我们将得到:
{"ft": [[1.0, 2.0], [3.0, -1.0]]}
可见返回的值是一个[2,2]的矩阵,如果返回的长度不足给定的长度,那么将会使用默认值去填充。
【注意:】
事实上,在TensorFlow1.0环境下,根据官方文档上的内容,我们是能够得到VarLenFeature的值,但是得不到FixLenFeature的值,因此建议如果使用定长的FixedLenFeature,一定要保证对应的数据是等长的。
做个试验来说明:
#coding=utf-8
import tensorflow as tf
import os
keys=[[1.0],[],[2.0,3.0]]
sess=tf.InteractiveSession()
sess.run(tf.global_variables_initializer())
def make_example(key):
example = tf.train.Example(features=tf.train.Features(
feature={
'ft':tf.train.Feature(float_list=tf.train.FloatList(value=key))
}
))
return example
filename="tmp.tfrecords"
if os.path.exists(filename):
os.remove(filename)
writer = tf.python_io.TFRecordWriter(filename)
for key in keys:
ex = make_example(key)
writer.write(ex.SerializeToString())
writer.close()
reader = tf.TFRecordReader()
filename_queue = tf.train.string_input_producer(["tmp.tfrecords"],num_epochs=1)
_,serialized_example =reader.read(filename_queue)
# coord = tf.train.Coordinator()
# threads = tf.train.start_queue_runners(sess=sess,coord=coord)
batch = tf.train.batch(tensors=[serialized_example],batch_size=3)
features={
"ft":tf.VarLenFeature(tf.float32)
}
#key_parsed = tf.parse_single_example(make_example([1,2,3]).SerializeToString(),features)
key_parsed = tf.parse_example(batch,features)
#start the queue
print tf.contrib.learn.run_n(key_parsed)
#[]means scalar
features={
"ft":tf.FixedLenFeature(shape=[2],dtype=tf.float32)
}
key_parsed = tf.parse_example(batch,features)
print tf.contrib.learn.run_n(key_parsed)
结果返回如下:
[{'ft': SparseTensorValue(indices=array([[0, 0],
[2, 0],
[2, 1]]), values=array([ 1., 2., 3.], dtype=float32), dense_shape=array([3, 2]))}]
InvalidArgumentError (see above for traceback): Name: <unknown>, Key: ft, Index: 0. Number of float values != expected. Values size: 1 but output shape: [2]
可见,对于VarLenFeature,是能返回正常结果的,但是对于FixedLenFeature则返回size不对,可见如果对于边长的数据还是不要使用FixedLenFeature为好。
如果把数据设置为[[1.0,2.0],[2.0,3.0]],那么FixedLenFeature返回的是:
[{'ft': array([[ 1., 2.],
[ 2., 3.]], dtype=float32)}]
这是正确的结果。
SparseFeature可以从下面的例子来说明:
`serialized`:
```
[
features {
feature { key: "val" value { float_list { value: [ 0.5, -1.0 ] } } }
feature { key: "ix" value { int64_list { value: [ 3, 20 ] } } }
},
features {
feature { key: "val" value { float_list { value: [ 0.0 ] } } }
feature { key: "ix" value { int64_list { value: [ 42 ] } } }
}
]
```
And arguments
```
example_names: ["input0", "input1"],
features: {
"sparse": SparseFeature(
index_key="ix", value_key="val", dtype=tf.float32, size=100),
}
```
Then the output is a dictionary:
```python
{
"sparse": SparseTensor(
indices=[[0, 3], [0, 20], [1, 42]],
values=[0.5, -1.0, 0.0]
dense_shape=[2, 100]),
}
```
现在明白了Example的协议和tf.parse_example的方法之后,我们再看看看几个简单的parse_example
tf.parse_single_example
区别于tf.parse_example,tf.parse_single_example只是少了一个batch而已,其余的都是一样的,我们看代码:
#coding=utf-8
import tensorflow as tf
import os
sess=tf.InteractiveSession()
sess.run(tf.global_variables_initializer())
def make_example(key):
example = tf.train.Example(features=tf.train.Features(
feature={
'ft':tf.train.Feature(float_list=tf.train.FloatList(value=key))
}
))
return example
features={
"ft":tf.FixedLenFeature(shape=[3],dtype=tf.float32)
}
key_parsed = tf.parse_single_example(make_example([1.0,2.0,3.0]).SerializeToString(),features)
print tf.contrib.learn.run_n(key_parsed)
结果返回为:
[{'ft': array([ 1., 2., 3.], dtype=float32)}]
tf.parse_single_sequence_example
tf.parse_single_sequence_example对应的是tf.train,SequenceExample,我们以下面代码说明,single_sequence_example的用法:
#coding=utf-8
import tensorflow as tf
import os
keys=[[1.0,2.0],[2.0,3.0]]
sess=tf.InteractiveSession()
sess.run(tf.global_variables_initializer())
def make_example(locale,age,score,times):
example = tf.train.SequenceExample(
context=tf.train.Features(
feature={
"locale":tf.train.Feature(bytes_list=tf.train.BytesList(value=[locale])),
"age":tf.train.Feature(int64_list=tf.train.Int64List(value=[age]))
}),
feature_lists=tf.train.FeatureLists(
feature_list={
"movie_rating":tf.train.FeatureList(feature=[tf.train.Feature(float_list=tf.train.FloatList(value=score)) for i in range(times)])
}
)
)
return example.SerializeToString()
context_features = {
"locale": tf.FixedLenFeature([],dtype=tf.string),
"age": tf.FixedLenFeature([],dtype=tf.int64)
}
sequence_features = {
"movie_rating": tf.FixedLenSequenceFeature([3], dtype=tf.float32,allow_missing=True)
}
context_parsed, sequence_parsed = tf.parse_single_sequence_example(make_example("china",24,[1.0,3.5,4.0],2),context_features=context_features,sequence_features=sequence_features)
print tf.contrib.learn.run_n(context_parsed)
print tf.contrib.learn.run_n(sequence_parsed)
结果打印为:
[{'locale': 'china', 'age': 24}]
[{'movie_rating': array([[ 1. , 3.5, 4. ],
[ 1. , 3.5, 4. ]], dtype=float32)}]
tf.parse_single_sequence_example的自动补齐
在常用的文本处理方面,由于文本经常是非定长的,因此需要经常补齐操作,例如使用CNN进行文本分类的时候就需要进行padding操作,通常我们把padding的索引设置为0,而且在文本预处理的时候也需要额外的代码进行处理,而TensorFlow提供了一个比较好的自动补齐工具,就是在tf.train.batch里面把参数dynamic_pad设置成True,样例如下:
#coding=utf-8
import tensorflow as tf
import os
keys=[[1,2],[2]]
sess=tf.InteractiveSession()
sess.run(tf.global_variables_initializer())
def make_example(key):
example = tf.train.SequenceExample(
context=tf.train.Features(
feature={
"length":tf.train.Feature(int64_list=tf.train.Int64List(value=[len(key)]))
}),
feature_lists=tf.train.FeatureLists(
feature_list={
"index":tf.train.FeatureList(feature=[tf.train.Feature(int64_list=tf.train.Int64List(value=[key[i]])) for i in range(len(key))])
}
)
)
return example.SerializeToString()
filename="tmp.tfrecords"
if os.path.exists(filename):
os.remove(filename)
writer = tf.python_io.TFRecordWriter(filename)
for key in keys:
ex = make_example(key)
writer.write(ex)
writer.close()
reader = tf.TFRecordReader()
filename_queue = tf.train.string_input_producer(["tmp.tfrecords"],num_epochs=1)
_,serialized_example =reader.read(filename_queue)
# coord = tf.train.Coordinator()
# threads = tf.train.start_queue_runners(sess=sess,coord=coord)
context_features={
"length":tf.FixedLenFeature([],dtype=tf.int64)
}
sequence_features={
"index":tf.FixedLenSequenceFeature([],dtype=tf.int64)
}
context_parsed, sequence_parsed = tf.parse_single_sequence_example(
serialized=serialized_example,
context_features=context_features,
sequence_features=sequence_features
)
batch_data = tf.train.batch(tensors=[sequence_parsed['index']],batch_size=2,dynamic_pad=True)
result = tf.contrib.learn.run_n({"index":batch_data})
print result
打印结果如下:
[{'index': array([[1, 2],
[2, 0]])}]
可见还是比较好用的功能
tensorflow的TFRecords读取
在上面的部分,我们展示了关于tensorflow的example的用法和解析过程,那么我们该如何使用它们呢?其实在上面的几段代码里面也有体现,就是TFRecords进行读写,TFRecords读写其实很简单,tensorflow提供了两个方法:
tf.TFRecordReader
tf.TFRecordWriter
首先我们看下第二个,也就是tf.TFRecordWritre,之所以先看第二个的原因是第一个Reader将和batch一起在下一节讲述。
关于TFRecordWriter,可以用下面代码说明,假设serilized_object是一个已经序列化好的example,那么其写的过程如下:
writer = tf.python_io.TFRecordWriter(filename) writer.write(serilized_object) writer.close()
tensorflow的多线程batch读取
这一节主要关注的是基于TFRecords的读取的方法和batch操作,我们可以回看一下之前的文章的batch操作:
Batching def read_my_file_format(filename_queue): reader = tf.SomeReader() key, record_string = reader.read(filename_queue) example, label = tf.some_decoder(record_string) processed_example = some_processing(example) return processed_example, label def input_pipeline(filenames, batch_size, num_epochs=None): filename_queue = tf.train.string_input_producer( filenames, num_epochs=num_epochs, shuffle=True) example, label = read_my_file_format(filename_queue) # min_after_dequeue defines how big a buffer we will randomly sample # from -- bigger means better shuffling but slower start up and more # memory used. # capacity must be larger than min_after_dequeue and the amount larger # determines the maximum we will prefetch. Recommendation: # min_after_dequeue + (num_threads + a small safety margin) * batch_size min_after_dequeue = 10000 capacity = min_after_dequeue + 3 * batch_size example_batch, label_batch = tf.train.shuffle_batch( [example, label], batch_size=batch_size, capacity=capacity, min_after_dequeue=min_after_dequeue) return example_batch, label_batch
这里我们把tf.SomeReader()换成tf.TFRecordReader()即可,然后再把tf.some_decoder换成我们自定义的decoder,当然在decoder里面我们可以自己指定parser(也就是上文提到的内容),然后我们使用tf.train.batch或者tf.train.shuffle_batch等操作获取到我们需要送入网络训练的batch参数即可。
多线程读取batch实例
我使用了softmax回归做一个简单的示例,下面是一个多线程读取batch的实例主要代码:
#coding=utf-8
"""
author:luchi
date:24/4/2017
desc:training logistic regression
"""
import tensorflow as tf
from model import Logistic
def read_my_file_format(filename_queue):
reader = tf.TFRecordReader()
_,serilized_example = reader.read(filename_queue)
#parsing example
features = tf.parse_single_example(serilized_example,
features={
"data":tf.FixedLenFeature([2],tf.float32),
"label":tf.FixedLenFeature([],tf.int64)
}
)
#decode from raw data,there indeed do not to change ,but to show common step , i write a case here
# data = tf.cast(features['data'],tf.float32)
# label = tf.cast(features['label'],tf.int64)
return features['data'],features['label']
def input_pipeline(filenames, batch_size, num_epochs=100):
filename_queue = tf.train.string_input_producer([filenames],num_epochs=num_epochs)
data,label=read_my_file_format(filename_queue)
datas,labels = tf.train.shuffle_batch([data,label],batch_size=batch_size,num_threads=5,
capacity=1000+3*batch_size,min_after_dequeue=1000)
return datas,labels
class config():
data_dim=2
label_num=2
learining_rate=0.1
init_scale=0.01
def run_training():
with tf.Graph().as_default(), tf.Session() as sess:
datas,labels = input_pipeline("reg.tfrecords",32)
c = config()
initializer = tf.random_uniform_initializer(-1*c.init_scale,1*c.init_scale)
with tf.variable_scope("model",initializer=initializer):
model = Logistic(config=c,data=datas,label=labels)
fetches = [model.train_op,model.accuracy,model.loss]
feed_dict={}
#init
init_op = tf.group(tf.global_variables_initializer(),
tf.local_variables_initializer())
sess.run(init_op)
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(sess=sess,coord=coord)
try:
while not coord.should_stop():
# fetches = [model.train_op,model.accuracy,model.loss]
# feed_dict={}
# feed_dict[model.data]=sess.run(datas)
# feed_dict[model.label]=sess.run(labels)
# _,accuracy,loss= sess.run(fetches,feed_dict)
_,accuracy,loss= sess.run(fetches,feed_dict)
print("the loss is %f and the accuracy is %f"%(loss,accuracy))
except tf.errors.OutOfRangeError:
print("done training")
finally:
coord.request_stop()
coord.join(threads)
sess.close()
def main():
run_training()
if __name__=='__main__':
main()
这里有几个坑需要说明一下:
使用了string_input_producer指定num_epochs之后,在初始化的时候需要使用:
init_op = tf.group(tf.global_variables_initializer(), tf.local_variables_initializer()) sess.run(init_op)
要不然会报错
2. 使用了从文件读取batch之后,就不需要设置tf.placeholder了【非常重要】,我在这个坑里呆了好久,如果使用了tf.placeholder一是会报错为tensor对象能送入到tf.placeholder中,另外一个是就算使用sess.run(batch_data),也会存在模型不能收敛的问题,所以切记切记
结果显示如下:
the loss is 0.156685 and the accuracy is 0.937500 the loss is 0.185438 and the accuracy is 0.968750 the loss is 0.092628 and the accuracy is 0.968750 the loss is 0.059271 and the accuracy is 1.000000 the loss is 0.088685 and the accuracy is 0.968750 the loss is 0.271341 and the accuracy is 0.968750 the loss is 0.244190 and the accuracy is 0.968750 the loss is 0.136841 and the accuracy is 0.968750 the loss is 0.115607 and the accuracy is 0.937500 the loss is 0.080254 and the accuracy is 1.000000
完整的代码见我的GitHub
以上这篇基于Tensorflow高阶读写教程就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持。
免责声明:本站资源来自互联网收集,仅供用于学习和交流,请遵循相关法律法规,本站一切资源不代表本站立场,如有侵权、后门、不妥请联系本站删除!
更新日志
- 凤飞飞《我们的主题曲》飞跃制作[正版原抓WAV+CUE]
- 刘嘉亮《亮情歌2》[WAV+CUE][1G]
- 红馆40·谭咏麟《歌者恋歌浓情30年演唱会》3CD[低速原抓WAV+CUE][1.8G]
- 刘纬武《睡眠宝宝竖琴童谣 吉卜力工作室 白噪音安抚》[320K/MP3][193.25MB]
- 【轻音乐】曼托凡尼乐团《精选辑》2CD.1998[FLAC+CUE整轨]
- 邝美云《心中有爱》1989年香港DMIJP版1MTO东芝首版[WAV+CUE]
- 群星《情叹-发烧女声DSD》天籁女声发烧碟[WAV+CUE]
- 刘纬武《睡眠宝宝竖琴童谣 吉卜力工作室 白噪音安抚》[FLAC/分轨][748.03MB]
- 理想混蛋《Origin Sessions》[320K/MP3][37.47MB]
- 公馆青少年《我其实一点都不酷》[320K/MP3][78.78MB]
- 群星《情叹-发烧男声DSD》最值得珍藏的完美男声[WAV+CUE]
- 群星《国韵飘香·贵妃醉酒HQCD黑胶王》2CD[WAV]
- 卫兰《DAUGHTER》【低速原抓WAV+CUE】
- 公馆青少年《我其实一点都不酷》[FLAC/分轨][398.22MB]
- ZWEI《迟暮的花 (Explicit)》[320K/MP3][57.16MB]