本文实例讲述了Python利用逻辑回归模型解决MNIST手写数字识别问题。分享给大家供大家参考,具体如下:
1、MNIST手写识别问题
MNIST手写数字识别问题:输入黑白的手写阿拉伯数字,通过机器学习判断输入的是几。可以通过TensorFLow下载MNIST手写数据集,通过import引入MNIST数据集并进行读取,会自动从网上下载所需文件。
%matplotlib inline
import tensorflow as tf
import tensorflow.examples.tutorials.mnist.input_data as input_data
mnist=input_data.read_data_sets('MNIST_data/',one_hot=True)
import matplotlib.pyplot as plt
def plot_image(image): #图片显示函数
plt.imshow(image.reshape(28,28),cmap='binary')
plt.show()
print("训练集数量:",mnist.train.num_examples,
"特征值组成:",mnist.train.images.shape,
"标签组成:",mnist.train.labels.shape)
batch_images,batch_labels=mnist.train.next_batch(batch_size=10) #批量读取数据
print(batch_images.shape,batch_labels.shape)
print('标签值:',np.argmax(mnist.train.labels[1000]),end=' ') #np.argmax()得到实际值
print('独热编码表示:',mnist.train.labels[1000])
plot_image(mnist.train.images[1000]) #显示数据集中第1000张图片

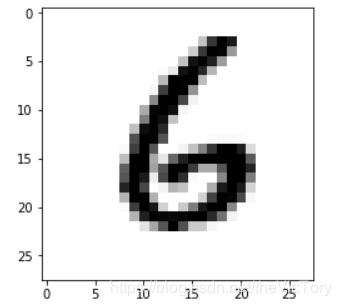
输出训练集 的数量有55000个,并打印特征值的shape为(55000,784),其中784代表每张图片由28*28个像素点组成,由于是黑白图片,每个像素点只有黑白单通道,即通过784个数可以描述一张图片的特征值。可以将图片在Jupyter中输出,将784个特征值reshape为28×28的二维数组,传给plt.imshow()函数,之后再通过show()输出。
MNIST提供next_batch()方法用于批量读取数据集,例如上面批量读取10个对应的images与labels数据并分别返回。该方法会按顺序一直往后读取,直到结束后会自动打乱数据,重新继续读取。
在打开mnist数据集时,第二个参数设置one_hot,表示采用独热编码方式打开。独热编码是一种稀疏向量,其中一个元素为1,其他元素均为0,常用于表示有限个可能的组合情况。例如数字6的独热编码为第7个分量为1,其他为0的数组。可以通过np.argmax()函数返回数组最大值的下标,即独热编码表示的实际数字。通过独热编码可以将离散特征的某个取值对应欧氏空间的某个点,有利于机器学习中特征之间的距离计算
数据集的划分,一种划分为训练集用于模型的训练,测试集用于结果的测试,要求集合数量足够大,而且具有代表性。但是在多次执行后,会导致模型向测试集数据进行拟合,从而导致测试集数据失去了测试的效果。因此将数据集进一步划分为训练集、验证集、测试集,将训练后的模型用验证集验证,当多次迭代结束之后再拿测试集去测试。MNIST数据集中的训练集为mnist.train,验证集为mnist.validation,测试集为mnist.test
2、逻辑回归
与线性回归相对比,房价预测是根据多个输入参数x与对应权重w相乘再加上b得到线性的输出房价。而还有许多问题的输出是非线性的、控制在[0,1]之间的,比如判断邮件是否为垃圾邮件,手写数字为0~9等,逻辑回归就是用于处理此类问题。例如电子邮件分类器输出0.8,表示该邮件为垃圾邮件的概率是0.8.
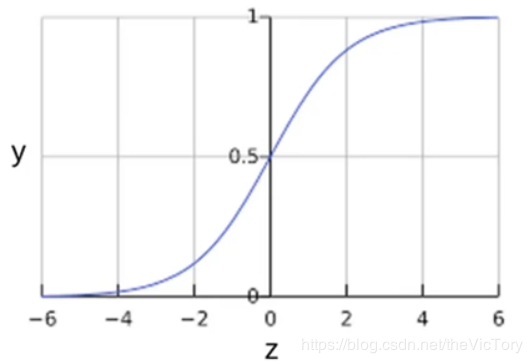
逻辑回归通过Sigmoid函数保证输出的值在[0,1]之间,该函数可以将全体实数映射到[0,1],从而将线性的输出转换为[0,1]的数。其定义与图像如下:

在逻辑回归中如果采用均方差的损失函数,带入sigmoid会得到一个非凸函数,这类函数会有多个极小值,采用梯度下降法便无法求得最优解。因此在逻辑回归中采用对数损失函数 ,其中y是特征值x的标签,y'是预测值。
,其中y是特征值x的标签,y'是预测值。
在手写数字识别中,通过单层神经元产生连续的输出值y,将y再输入到softmax层处理,经过函数计算将结果映射为0~9每个数字对应的概率,概率越大表示该图片越像某个数字,所有数字的概率之和为1

交叉熵损失函数:交叉熵用于刻画两个概率分布之间的距离 ,其中p代表正确答案,q代表预测值,交叉熵越小距离越近,从而模型的预测越准确。例如正确答案为(1,0,0),甲模型预测为(0.5,0.2,0.3),其交叉熵=-1*log0.5≈0.3,乙模型(0.7,0.1,0.2),其交叉熵=-1*log0.7≈0.15,所以乙模型预测更准确
,其中p代表正确答案,q代表预测值,交叉熵越小距离越近,从而模型的预测越准确。例如正确答案为(1,0,0),甲模型预测为(0.5,0.2,0.3),其交叉熵=-1*log0.5≈0.3,乙模型(0.7,0.1,0.2),其交叉熵=-1*log0.7≈0.15,所以乙模型预测更准确
模型的训练
首先定义二维浮点数占位符x、y,以及二维参数变量W、b并随机赋初值。之后定义前向计算为向量x与W对应叉乘再加b,并将得到的线性结果经过softmax处理得到独热编码预测值。
之后定义准确率accuracy,其值为预测值pred与真实值y相等个数来衡量
接下来初始化变量、设置超参数,并定义损失函数、优化器,之后开始训练。每轮训练中分批次读取数据进行训练,每轮训练结束后输出损失与准确率。
import numpy as np
import tensorflow as tf
import tensorflow.examples.tutorials.mnist.input_data as input_data
mnist=input_data.read_data_sets('MNIST_data/',one_hot=True)
import matplotlib.pyplot as plt
#定义占位符、变量、前向计算
x=tf.placeholder(tf.float32,[None,784],name='x')
y=tf.placeholder(tf.float32,[None,10],name='y')
W=tf.Variable(tf.random_normal([784,10]),name='W')
b=tf.Variable(tf.zeros([10]),name='b')
forward=tf.matmul(x,W)+b
pred=tf.nn.softmax(forward) #通过softmax将线性结果分类处理
#计算预测值与真实值的匹配个数
correct_prediction=tf.equal(tf.argmax(pred,1),tf.argmax(y,1))
#将上一步得到的布尔值转换为浮点数,并求平均值,得到准确率
accuracy=tf.reduce_mean(tf.cast(correct_prediction,tf.float32))
ss=tf.Session()
init=tf.global_variables_initializer()
ss.run(init)
#超参数设置
train_epochs=50
batch_size=100 #每个批次的样本数
batch_num=int(mnist.train.num_examples/batch_size) #一轮需要训练多少批
learning_rate=0.01
#定义交叉熵损失函数、梯度下降优化器
loss_function=tf.reduce_mean(-tf.reduce_sum(y*tf.log(pred),reduction_indices=1))
optimizer=tf.train.GradientDescentOptimizer(learning_rate).minimize(loss_function)
for epoch in range(train_epochs):
for batch in range(batch_num): #分批次读取数据进行训练
xs,ys=mnist.train.next_batch(batch_size)
ss.run(optimizer,feed_dict={x:xs,y:ys})
#每轮训练结束后通过带入验证集的数据,检测模型的损失与准去率
loss,acc=ss.run([loss_function,accuracy], feed_dict={x:mnist.validation.images,y:mnist.validation.labels})
print('第%2d轮训练:损失为:%9f,准确率:%.4f'%(epoch+1,loss,acc))
从每轮训练结果可以看出损失在逐渐下降,准确率在逐步上升。

结果预测
使用训练好的模型对测试集中的数据进行预测,即将mnist.test.images数据带入去求pred的值。
为了使结果更便于显示,可以借助plot函数库将图片数据显示出来,并配以文字label与predic的值。首先通过plt.gcf()得到一副图像资源并设置其大小。再通过plt.subplot(5,5,index+1)函数将其划分为5×5个子图,遍历第index+1个子图,分别将图像资源绘制到子图,通过set_title()设置每个子图的title显示内容。子图绘制结束后显示整个图片,并调用函数传入图片、标签、预测值等参数。
prediction=ss.run(tf.argmax(pred,1),feed_dict={x:mnist.test.images})
def show_result(images,labels,prediction,index,num=10): #绘制图形显示预测结果
pic=plt.gcf() #获取当前图像
pic.set_size_inches(10,12) #设置图片大小
for i in range(0,num):
sub_pic=plt.subplot(5,5,i+1) #获取第i个子图
#将第index个images信息显示到子图上
sub_pic.imshow(np.reshape(images[index],(28,28)),cmap='binary')
title="label:"+str(np.argmax(labels[index])) #设置子图的title内容
if len(prediction)>0:
title+=",predict:"+str(prediction[index])
sub_pic.set_title(title,fontsize=10)
sub_pic.set_xticks([]) #设置x、y坐标轴不显示
sub_pic.set_yticks([])
index+=1
plt.show()
show_result(mnist.test.images,mnist.test.labels,prediction,10)
运行结果如下,可以看到预测的结果大多准确

更多关于Python相关内容感兴趣的读者可查看本站专题:《Python数据结构与算法教程》、《Python加密解密算法与技巧总结》、《Python编码操作技巧总结》、《Python函数使用技巧总结》、《Python字符串操作技巧汇总》及《Python入门与进阶经典教程》
希望本文所述对大家Python程序设计有所帮助。
免责声明:本站资源来自互联网收集,仅供用于学习和交流,请遵循相关法律法规,本站一切资源不代表本站立场,如有侵权、后门、不妥请联系本站删除!
更新日志
- 凤飞飞《我们的主题曲》飞跃制作[正版原抓WAV+CUE]
- 刘嘉亮《亮情歌2》[WAV+CUE][1G]
- 红馆40·谭咏麟《歌者恋歌浓情30年演唱会》3CD[低速原抓WAV+CUE][1.8G]
- 刘纬武《睡眠宝宝竖琴童谣 吉卜力工作室 白噪音安抚》[320K/MP3][193.25MB]
- 【轻音乐】曼托凡尼乐团《精选辑》2CD.1998[FLAC+CUE整轨]
- 邝美云《心中有爱》1989年香港DMIJP版1MTO东芝首版[WAV+CUE]
- 群星《情叹-发烧女声DSD》天籁女声发烧碟[WAV+CUE]
- 刘纬武《睡眠宝宝竖琴童谣 吉卜力工作室 白噪音安抚》[FLAC/分轨][748.03MB]
- 理想混蛋《Origin Sessions》[320K/MP3][37.47MB]
- 公馆青少年《我其实一点都不酷》[320K/MP3][78.78MB]
- 群星《情叹-发烧男声DSD》最值得珍藏的完美男声[WAV+CUE]
- 群星《国韵飘香·贵妃醉酒HQCD黑胶王》2CD[WAV]
- 卫兰《DAUGHTER》【低速原抓WAV+CUE】
- 公馆青少年《我其实一点都不酷》[FLAC/分轨][398.22MB]
- ZWEI《迟暮的花 (Explicit)》[320K/MP3][57.16MB]