项目描述:

在该项目中,你将使用强化学习算法,实现一个自动走迷宫机器人。
如上图所示,智能机器人显示在右上角。在我们的迷宫中,有陷阱(红色×××)及终点(蓝色的目标点)两种情景。机器人要尽量避开陷阱、尽快到达目的地。
小车可执行的动作包括:向上走 u、向右走 r、向下走 d、向左走l。
执行不同的动作后,根据不同的情况会获得不同的奖励,具体而言,有以下几种情况。
- 撞到墙壁:-10
- 走到终点:50
- 走到陷阱:-30
- 其余情况:-0.1
我们需要通过修改 robot.py 中的代码,来实现一个 Q Learning 机器人,实现上述的目标。
Section 1 算法理解
1.1 强化学习总览
强化学习作为机器学习算法的一种,其模式也是让智能体在“训练”中学到“经验”,以实现给定的任务。但不同于监督学习与非监督学习,在强化学习的框架中,我们更侧重通过智能体与环境的交互来学习。通常在监督学习和非监督学习任务中,智能体往往需要通过给定的训练集,辅之以既定的训练目标(如最小化损失函数),通过给定的学习算法来实现这一目标。然而在强化学习中,智能体则是通过其与环境交互得到的奖励进行学习。这个环境可以是虚拟的(如虚拟的迷宫),也可以是真实的(自动驾驶汽车在真实道路上收集数据)。
在强化学习中有五个核心组成部分,它们分别是:环境(Environment)、智能体(Agent)、状态(State)、动作(Action)和奖励(Reward)。在某一时间节点t:
智能体在从环境中感知其所处的状态
智能体根据某些准则选择动作 
环境根据智能体选择的动作,向智能体反馈奖励 
通过合理的学习算法,智能体将在这样的问题设置下,成功学到一个在状态 选择动作 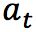 的策略 。
的策略 。
1.2 计算Q值
在我们的项目中,我们要实现基于 Q-Learning 的强化学习算法。Q-Learning 是一个值迭代(Value Iteration)算法。与策略迭代(Policy Iteration)算法不同,值迭代算法会计算每个”状态“或是”状态-动作“的值(Value)或是效用(Utility),然后在执行动作的时候,会设法最大化这个值。因此,对每个状态值的准确估计,是我们值迭代算法的核心。通常我们会考虑最大化动作的长期奖励,即不仅考虑当前动作带来的奖励,还会考虑动作长远的奖励。
在 Q-Learning 算法中,我们把这个长期奖励记为 Q 值,我们会考虑每个 ”状态-动作“ 的 Q 值,具体而言,它的计算公式为:

也就是对于当前的“状态-动作”  ,我们考虑执行动作
,我们考虑执行动作 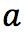 后环境给我们的奖励
后环境给我们的奖励 ,以及执行动作
,以及执行动作 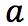 到达
到达  后,执行任意动作能够获得的最大的Q值
后,执行任意动作能够获得的最大的Q值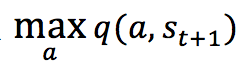 ,
, 为折扣因子。
为折扣因子。
不过一般地,我们使用更为保守地更新 Q 表的方法,即引入松弛变量 alpha,按如下的公式进行更新,使得 Q 表的迭代变化更为平缓。


根据已知条件求 。
。
已知:如上图,机器人位于 s1,行动为 u,行动获得的奖励与题目的默认设置相同。在 s2 中执行各动作的 Q 值为:u: -24,r: -13,d: -0.29、l: +40,γ取0.9。

1.3 如何选择动作
在强化学习中,「探索-利用」问题是非常重要的问题。具体来说,根据上面的定义,我们会尽可能地让机器人在每次选择最优的决策,来最大化长期奖励。但是这样做有如下的弊端:
- 在初步的学习中,我们的 Q 值会不准确,如果在这个时候都按照 Q 值来选择,那么会造成错误。
- 学习一段时间后,机器人的路线会相对固定,则机器人无法对环境进行有效的探索。
因此我们需要一种办法,来解决如上的问题,增加机器人的探索。由此我们考虑使用 epsilon-greedy 算法,即在小车选择动作的时候,以一部分的概率随机选择动作,以一部分的概率按照最优的 Q 值选择动作。同时,这个选择随机动作的概率应当随着训练的过程逐步减小。
在如下的代码块中,实现 epsilon-greedy 算法的逻辑,并运行测试代码。
import random
import operator
actions = ['u','r','d','l']
qline = {'u':1.2, 'r':-2.1, 'd':-24.5, 'l':27}
epsilon = 0.3 # 以0.3的概率进行随机选择
def choose_action(epsilon):
action = None
if random.uniform(0,1.0) <= epsilon: # 以某一概率
action = random.choice(actions)# 实现对动作的随机选择
else:
action = max(qline.items(), key=operator.itemgetter(1))[0] # 否则选择具有最大 Q 值的动作
return action
range(100): res += choose_action(epsilon) print(res) res = '' for i in range(100): res += choose_action(epsilon) print(res) ldllrrllllrlldlldllllllllllddulldlllllldllllludlldllllluudllllllulllllllllllullullllllllldlulllllrlr
Section 2 代码实现
2.1 Maze 类理解
我们首先引入了迷宫类 Maze,这是一个非常强大的函数,它能够根据你的要求随机创建一个迷宫,或者根据指定的文件,读入一个迷宫地图信息。
- 使用
Maze("file_name")根据指定文件创建迷宫,或者使用Maze(maze_size=(height, width))来随机生成一个迷宫。 - 使用
trap number参数,在创建迷宫的时候,设定迷宫中陷阱的数量。 - 直接键入迷宫变量的名字按回车,展示迷宫图像(如
g=Maze("xx.txt"),那么直接输入g即可。 - 建议生成的迷宫尺寸,长在 6~12 之间,宽在 10~12 之间。
在如下的代码块中,创建你的迷宫并展示。
from Maze import Maze %matplotlib inline %confer InlineBackend.figure_format = 'retina' ## to-do: 创建迷宫并展示 g=Maze(maze_size=(6,8), trap_number=1) g Maze of size (12, 12 )

你可能已经注意到,在迷宫中我们已经默认放置了一个机器人。实际上,我们为迷宫配置了相应的 API,来帮助机器人的移动与感知。其中你随后会使用的两个 API 为 maze.sense_robot() 及 maze.move_robot() 。
maze.sense_robot()为一个无参数的函数,输出机器人在迷宫中目前的位置。maze.move_robot(direction)对输入的移动方向,移动机器人,并返回对应动作的奖励值。
随机移动机器人,并记录下获得的奖励,展示出机器人最后的位置。
rewards = [] ## 循环、随机移动机器人10次,记录下奖励 for i in range(10): res = g.move_robot(random. Choice(actions)) rewards.append(res) ## 输出机器人最后的位置 print(g.sense_robot()) ## 打印迷宫,观察机器人位置 g (0,9)

2.2 Robot 类实现
Robot 类是我们需要重点实现的部分。在这个类中,我们需要实现诸多功能,以使得我们成功实现一个强化学习智能体。总体来说,之前我们是人为地在环境中移动了机器人,但是现在通过实现 Robot 这个类,机器人将会自己移动。通过实现学习函数,Robot 类将会学习到如何选择最优的动作,并且更新强化学习中对应的参数。
首先 Robot 有多个输入,其中 alpha=0.5, gamma=0.9, epsilon0=0.5 表征强化学习相关的各个参数的默认值,这些在之前你已经了解到,Maze 应为机器人所在迷宫对象。
随后观察 Robot.update 函数,它指明了在每次执行动作时,Robot 需要执行的程序。按照这些程序,各个函数的功能也就明了了。
运行如下代码检查效果(记得将 maze 变量修改为你创建迷宫的变量名)。
import random
import operator
class Robot(object):
def __init__(self, maze, alpha=0.5, gamma=0.9, epsilon0=0.5):
self. Maze = maze
self.valid_actions = self.maze.valid_actions
self.state = None
self.action = None
# Set Parameters of the Learning Robot
self.alpha = alpha
self.gamma = gamma
self.epsilon0 = epsilon0
self. Epsilon = epsilon0
self.t = 0
self.Qtable = {}
self. Reset()
def. reset(self):
"""
Reset the robot
"""
self.state = self.sense_state()
self.create_Qtable_line(self.state)
def. set status(self, learning=False, testing=False):
"""
Determine whether the robot is learning its q table, or
executing the testing procedure.
"""
self. Learning = learning
self.testing = testing
def. update_parameter(self):
"""
Some of the paramters of the q learning robot can be altered,
update these parameters when necessary.
"""
if self.testing:
# TODO 1. No random choice when testing
self. Epsilon = 0
else:
# TODO 2. Update parameters when learning
self. Epsilon *= 0.95
return self. Epsilon
def. sense_state(self):
"""
Get the current state of the robot. In this
"""
# TODO 3. Return robot's current state
return self.maze.sense_robot()
def. create_Qtable_line(self, state):
"""
Create the qtable with the current state
"""
# TODO 4. Create qtable with current state
# Our qtable should be a two level dict,
# Qtable[state] ={'u':xx, 'd':xx, ...}
# If Qtable[state] already exits, then do
# not change it.
self.Qtable.setdefault(state, {a: 0.0 for a in self.valid_actions})
def. choose_action(self):
"""
Return an action according to given rules
"""
def. is_random_exploration():
# TODO 5. Return whether do random choice
# hint: generate a random number, and compare
# it with epsilon
return random.uniform(0, 1.0) <= self. Epsilon
if self. Learning:
if is_random_exploration():
# TODO 6. Return random choose aciton
return random. Choice(self.valid_actions)
else:
# TODO 7. Return action with highest q value
return max(self.Qtable[self.state].items(), key=operator.itemgetter(1))[0]
elif self.testing:
# TODO 7. choose action with highest q value
return max(self.Qtable[self.state].items(), key=operator.itemgetter(1))[0]
else:
# TODO 6. Return random choose aciton
return random. Choice(self.valid_actions)
def. update_Qtable(self, r, action, next_state):
"""
Update the qtable according to the given rule.
"""
if self. Learning:
# TODO 8. When learning, update the q table according
# to the given rules
self.Qtable[self.state][action] = (1 - self.alpha) * self.Qtable[self.state][action] + self.alpha * (
r + self.gamma * max(self.Qtable[next_state].values()))
def. update(self):
"""
Describle the procedure what to do when update the robot.
Called every time in every epoch in training or testing.
Return current action and reward.
"""
self.state = self.sense_state() # Get the current state
self.create_Qtable_line(self.state) # For the state, create q table line
action = self.choose_action() # choose action for this state
reward = self.maze.move_robot(action) # move robot for given action
next_state = self.sense_state() # get next state
self.create_Qtable_line(next_state) # create q table line for next state
if self. Learning and not self.testing:
self.update_Qtable(reward, action, next_state) # update q table
self.update_parameter() # update parameters
return action, reward
# from Robot import Robot
# g=Maze(maze_size=(6,12), trap_number=2)
g=Maze("test_world\maze_01.txt")
robot = Robot(g) # 记得将 maze 变量修改为你创建迷宫的变量名
robot.set_status(learning=True,testing=False)
print(robot.update())
g
('d', -0.1)
Maze of size (12, 12)

2.3 用 Runner 类训练 Robot
在完成了上述内容之后,我们就可以开始对我们 Robot 进行训练并调参了。我们准备了又一个非常棒的类 Runner ,来实现整个训练过程及可视化。使用如下的代码,你可以成功对机器人进行训练。并且你会在当前文件夹中生成一个名为 filename 的视频,记录了整个训练的过程。通过观察该视频,你能够发现训练过程中的问题,并且优化你的代码及参数。
尝试利用下列代码训练机器人,并进行调参。可选的参数包括:
- 训练参数
- 训练次数
epoch
- 训练次数
- 机器人参数:
epsilon0(epsilon 初值)epsilon衰减(可以是线性、指数衰减,可以调整衰减的速度),你需要在 Robot.py 中调整alphagamma
- 迷宫参数:
- 迷宫大小
- 迷宫中陷阱的数量
- 可选的参数:
- epoch = 20
- epsilon0 = 0.5
- alpha = 0.5
- gamma = 0.9
- maze_size = (6,8)
- trap_number = 2
from Runner import Runner g = Maze(maze_size=maze_size,trap_number=trap_number) r = Robot(g,alpha=alpha, epsilon0=epsilon0, gamma=gamma) r.set_status(learning=True) runner = Runner(r, g) runner.run_training(epoch, display_direction=True) #runner.generate_movie(filename = "final1.mp4") # 你可以注释该行代码,加快运行速度,不过你就无法观察到视频了。 g

使用 runner.plot_results() 函数,能够打印机器人在训练过程中的一些参数信息。
- Success Times 代表机器人在训练过程中成功的累计次数,这应当是一个累积递增的图像。
- Accumulated Rewards 代表机器人在每次训练 epoch 中,获得的累积奖励的值,这应当是一个逐步递增的图像。
- Running Times per Epoch 代表在每次训练 epoch 中,小车训练的次数(到达终点就会停止该 epoch 转入下次训练),这应当是一个逐步递减的图像。
使用 runner.plot_results() 输出训练结果
runner.plot_results()

以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持。
免责声明:本站资源来自互联网收集,仅供用于学习和交流,请遵循相关法律法规,本站一切资源不代表本站立场,如有侵权、后门、不妥请联系本站删除!
这一波大模型产业落地浪潮里,不少企业其实处在 “干瞪眼“的状态。
一种情况是,很多大模型产品看得见却摸不着,在台上一个个遥遥领先——今天Sora技精四座,明天英伟达的机器人又赢得满堂彩,可是到了台下一问:啥时候能用上啊?答曰:遥遥无期。
另一种情况是,企业想用上大模型,却又难免瞻前顾后——既要考虑场景融合,又得兼顾安全性,还要考虑打通现有系统,再加上各种部署成本和繁琐的采购流程……最后只能拂袖:罢了,再等等吧。
稳了!魔兽国服回归的3条重磅消息!官宣时间再确认!
昨天有一位朋友在大神群里分享,自己亚服账号被封号之后居然弹出了国服的封号信息对话框。
这里面让他访问的是一个国服的战网网址,com.cn和后面的zh都非常明白地表明这就是国服战网。
而他在复制这个网址并且进行登录之后,确实是网易的网址,也就是我们熟悉的停服之后国服发布的暴雪游戏产品运营到期开放退款的说明。这是一件比较奇怪的事情,因为以前都没有出现这样的情况,现在突然提示跳转到国服战网的网址,是不是说明了简体中文客户端已经开始进行更新了呢?
更新日志
- 凤飞飞《我们的主题曲》飞跃制作[正版原抓WAV+CUE]
- 刘嘉亮《亮情歌2》[WAV+CUE][1G]
- 红馆40·谭咏麟《歌者恋歌浓情30年演唱会》3CD[低速原抓WAV+CUE][1.8G]
- 刘纬武《睡眠宝宝竖琴童谣 吉卜力工作室 白噪音安抚》[320K/MP3][193.25MB]
- 【轻音乐】曼托凡尼乐团《精选辑》2CD.1998[FLAC+CUE整轨]
- 邝美云《心中有爱》1989年香港DMIJP版1MTO东芝首版[WAV+CUE]
- 群星《情叹-发烧女声DSD》天籁女声发烧碟[WAV+CUE]
- 刘纬武《睡眠宝宝竖琴童谣 吉卜力工作室 白噪音安抚》[FLAC/分轨][748.03MB]
- 理想混蛋《Origin Sessions》[320K/MP3][37.47MB]
- 公馆青少年《我其实一点都不酷》[320K/MP3][78.78MB]
- 群星《情叹-发烧男声DSD》最值得珍藏的完美男声[WAV+CUE]
- 群星《国韵飘香·贵妃醉酒HQCD黑胶王》2CD[WAV]
- 卫兰《DAUGHTER》【低速原抓WAV+CUE】
- 公馆青少年《我其实一点都不酷》[FLAC/分轨][398.22MB]
- ZWEI《迟暮的花 (Explicit)》[320K/MP3][57.16MB]