
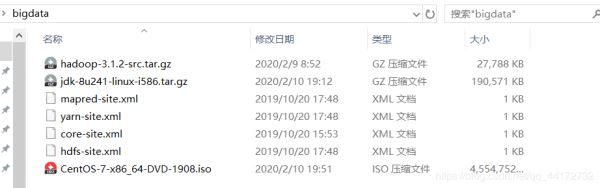
如上图 准备好该准备的食材(ps:其中的hadoop-3.1.2-src更改为hadoop-3.1.2
src为源文件的意思? 反正就是换了 大家注意一下 后面截图有错的地方有空我再改吧 肝疼)
安装好centos7

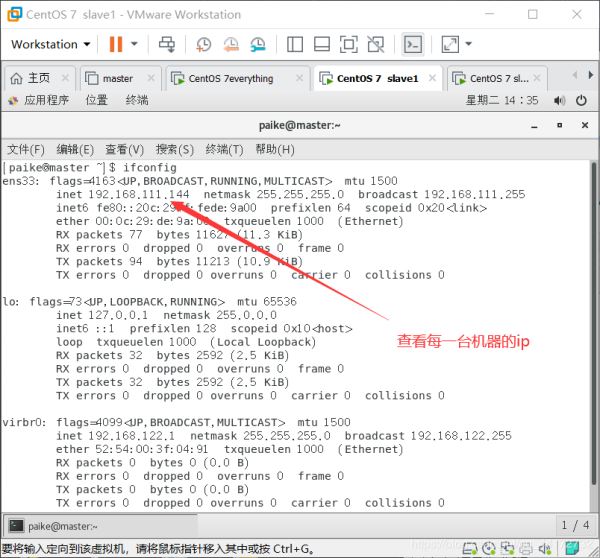
桌面右键打开terminal——输入ifconfig——查看ens33的ip——记住然后打开xftp6

点击新建



把食材多选,右键传输即可,内网传输速度不快不慢
所示很完美了

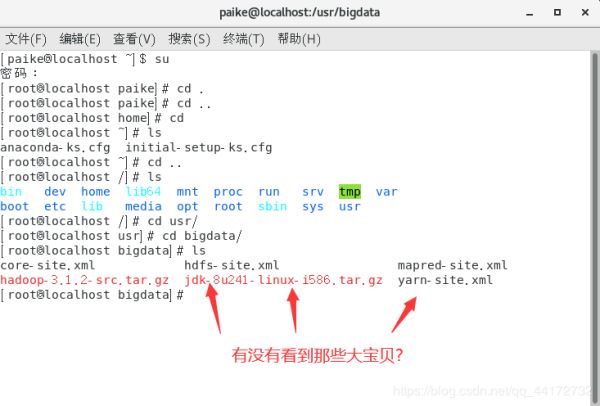

解压hadoop安装包 tar -zxvf hadoop-3.1.2-src.tar.gz

重新装了centos7 解压的时候分文件夹了

如上图编写

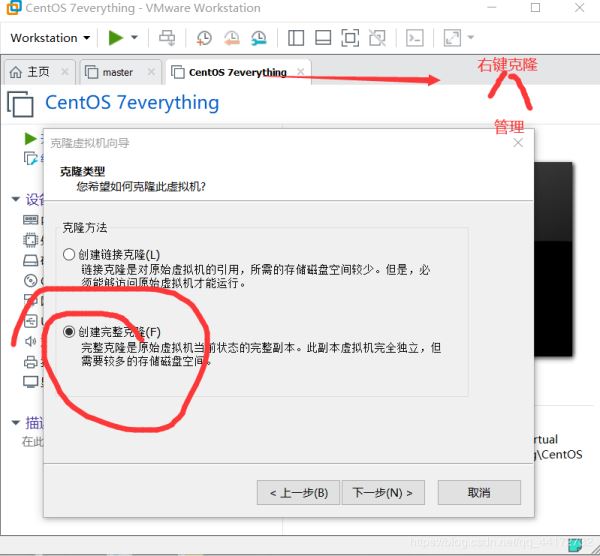

打开xshell 新建

输入你的主机ip 在用户身份验证上写上用户名和密码


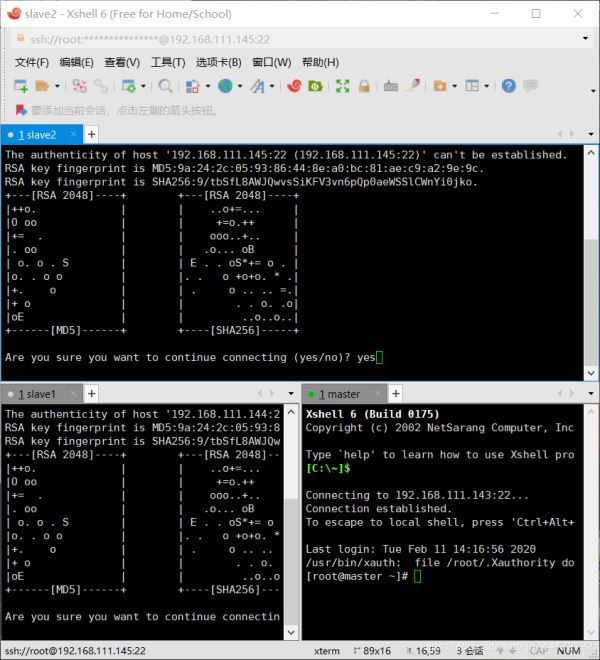
yes就完事了——然后三台机器都需要改了名字

时间同步 时区一致。要保证设置主机时间准确,每台机器时区必须一致。实验中我们需要同步网络时间,因此要首先选择一样的时区。先确保时区一样,否则同步以后时间也是有时区差。可以使用 date 命令查看自己的机器时间. 选择时区:tzselect

1.关闭防火墙
当其状态是 dead 时,即防火墙关闭。 关闭防火墙:systemctl stop firewalld 查看状态:systemctl status firewalld
2. hosts文件配置 (三台机器) 如下图输入各节点的ip

3. master 作为 ntp 服务器,修改 ntp 配置文件。(master 上执行)
vi /etc/ntp.conf server 127.127.1.0 # local clock fudge 127.127.1.0 stratum 10 #stratum 设置为其它值也是可以的,其范围为 0~15

重启 ntp 服务。 /bin/systemctl restart ntpd.service 其他机器同步(slave1,slave2) 等待大概五分钟,再到其他机上同步该 master 服务器时间。 ntpdate master 如果配置平台式没有外网连接可以将三台机器设为统一时间,输入命令: date -s 10:00(时间)

终于走到正题??? 别慌快了
1. SSH免密
(1)每个结点分别产生公私密钥:
ssh-keygen -t dsa -P ‘' -f ~/.ssh/id_dsa(三台机器)
秘钥产生目录在用户主目录下的.ssh 目录中,进入相应目录查看:
cd .ssh/

(2)Id_dsa.pub 为公钥,id_dsa 为私钥,紧接着将公钥文件复制成 authorized_keys 文 件:(仅 master)
cat id_dsa.pub authorized_keys(注意在.ssh/路径下操作)

在主机上连接自己,也叫做 ssh 内回环。
ssh master

(3)让主结点 master 能通过 SSH 免密码登录两个子结点 slave。(slave 中操作)
为了实现这个功能,两个 slave 结点的公钥文件中必须要包含主结点的公钥信息,这样
当 master 就可以顺利安全地访问这两个 slave 结点了。
slave1 结点通过 scp 命令远程登录 master 结点,并复制 master 的公钥文件到当前的目录
下,且重命名为 master_das.pub,这一过程需要密码验证。
scp master:~/.ssh/id_dsa.pub ./master_das.pub

将 master 结点的公钥文件追加至 authorized_keys 文件:
cat master_das.pub authorized_keys
(1)每个结点分别产生公私密钥: ssh-keygen -t dsa -P ‘' -f ~/.ssh/id_dsa(三台机器)秘钥产生目录在用户主目录下的.ssh 目录中,进入相应目录查看: cd .ssh/ (2)Id_dsa.pub 为公钥,id_dsa 为私钥,紧接着将公钥文件复制成 authorized_keys 文 件:(仅 master) cat id_dsa.pub authorized_keys(注意在.ssh/路径下操作) 在主机上连接自己,也叫做 ssh 内回环。 ssh master
 这时,
这时,
master 就可以连接 slave1 了。

slave1 结点首次连接时需要,“yes”确认连接,这意味着 master 结点连接 slave1 结点时需要人工询问,无法自动连接,输入 yes 后成功接入,紧接着注销退出至 master 结点。
同理 slave2 中也是这么操作
jdk之前已经安装好了,所以我们直接来配环境,就和windows的时候配环境变量一个道理(三台)
修改环境变量:vi /etc/profile > 添加内容如下: > export JAVA_HOME=/usr/java/jdk1.8.0_241 > export CLASSPATH=$JAVA_HOME/lib/export > PATH=$PATH:$JAVA_HOME/bin > export PATH JAVA_HOME CLASSPATH
生效环境变量:source /etc/profile
插播一个小技巧scp

scp /etc/profile slave1:/etc/profile ##这样就可以传给slave1 和slave2了
终于到hadoop了??? 恭喜宁!
配置环境变量: vi/etc/profile export HADOOP_HOME=/usr/hadoop/hadoop-3.1.2 export CLASSPATH=$CLASSPATH:$HADOOP_HOME/lib export PATH=$PATH:$HADOOP_HOME/bin
我经常忘的一步大声告诉我是什么!
使用以下命令使profile生效: source /etc/profile
温馨提示 下面就是配置文件的内容了 本文暂时不做讲解内容但是我已经给大家准备好标准的配置文件了

编辑hadoop环境配置文件hadoop-env.sh
export JAVA_HOME=/usr/java/jdk1.8.0_241 在这个文件里面会有好多注释的语句,找到你要配置的模板把井号删除完善即可 耐心找一下
然后我偷懒的地方就要到了!!!!!我上传了几个配置文件 我们复制到这个文件夹中即可 系统提示是否覆盖时候就输入y即可
core-site.xml yarn-site.xml hdfs-site.xml mapred-site.xml

还需要写一下slave文件 加上slave1 slave2如下图

还有master文件

(9)分发hadoop: scp -r /usr/hadoop root@slave1:/usr/ scp -r /usr/hadoop root@slave2:/usr/
master中格式化hadoop hadoop namenode -format 如果报错的话 看看是不是如下链接的错误 里面有解决办法
总结
以上所述是小编给大家介绍的hadoop基于Linux7的安装配置图文详解,希望对大家有所帮助!
免责声明:本站资源来自互联网收集,仅供用于学习和交流,请遵循相关法律法规,本站一切资源不代表本站立场,如有侵权、后门、不妥请联系本站删除!
P70系列延期,华为新旗舰将在下月发布
3月20日消息,近期博主@数码闲聊站 透露,原定三月份发布的华为新旗舰P70系列延期发布,预计4月份上市。
而博主@定焦数码 爆料,华为的P70系列在定位上已经超过了Mate60,成为了重要的旗舰系列之一。它肩负着重返影像领域顶尖的使命。那么这次P70会带来哪些令人惊艳的创新呢?
根据目前爆料的消息来看,华为P70系列将推出三个版本,其中P70和P70 Pro采用了三角形的摄像头模组设计,而P70 Art则采用了与上一代P60 Art相似的不规则形状设计。这样的外观是否好看见仁见智,但辨识度绝对拉满。
更新日志
- 小骆驼-《草原狼2(蓝光CD)》[原抓WAV+CUE]
- 群星《欢迎来到我身边 电影原声专辑》[320K/MP3][105.02MB]
- 群星《欢迎来到我身边 电影原声专辑》[FLAC/分轨][480.9MB]
- 雷婷《梦里蓝天HQⅡ》 2023头版限量编号低速原抓[WAV+CUE][463M]
- 群星《2024好听新歌42》AI调整音效【WAV分轨】
- 王思雨-《思念陪着鸿雁飞》WAV
- 王思雨《喜马拉雅HQ》头版限量编号[WAV+CUE]
- 李健《无时无刻》[WAV+CUE][590M]
- 陈奕迅《酝酿》[WAV分轨][502M]
- 卓依婷《化蝶》2CD[WAV+CUE][1.1G]
- 群星《吉他王(黑胶CD)》[WAV+CUE]
- 齐秦《穿乐(穿越)》[WAV+CUE]
- 发烧珍品《数位CD音响测试-动向效果(九)》【WAV+CUE】
- 邝美云《邝美云精装歌集》[DSF][1.6G]
- 吕方《爱一回伤一回》[WAV+CUE][454M]