测试修改前,先打包备份!
测试修改前,先打包备份!
测试修改前,先打包备份!
重要的事情说三遍
新手,网上东拼西凑了个脚本。
功能:批量搜索py脚本所在目录及子目录下的excel的xls文件,替换修改表格里内容。
[Python] 纯文本查看 复制代码
#!/usr/bin/python# -*- coding: utf-8 -*-# Date: 2022/01/08# testing System version: CentOS Linux release 7.8.2003 (Core)# Python version : 2.7.5 (default, Apr 2 2020, 13:16:51)# xlrd module version : 2.0.1# xlwt module version : 1.3.0# xlutils module version :2.0.0# 注意:1.只支持xls(excel 97/2003)文件,不支持xlsx(excel 2007/2010+)# 2.脚本中注释在实际使用时删掉,否则可能会在某些环境下有奇怪问题 import os,sysimport xlrd,xlwtfrom xlutils.copy import copy ## 旧的字符串old_str = ['pkgname','username','dbinfo','dbname']## 替换的新字符串,新旧列表中位置要对应new_str = ['PKGNAME','USERNAME','DBINFO','DBNAME'] ## 新旧字符串列表长度len_old_str = len(old_str)len_new_str = len(new_str)## 检查新旧字符串列表数量是否相等,不相等退出if len_old_str != len_new_str: print "\n[ Error ] 'old_str =",len_old_str,"' not eq 'new_str =",len_new_str,"'\n" sys.exit(); ## 小写转大写def str_to_STR( xls_list ): ## 读取Excle文件 wb = xlrd.open_workbook( xls_list ) ## 将uncode编码汉字显示成可读 reload(sys) sys.setdefaultencoding( "utf-8" ) ## 读取第1个索引的sheet页,索引0开始 sheet = wb.sheet_by_index(1) ## 读取excle里第一个sheet页,第10列(J列)内容,索引0开始 col = sheet.col_values(9) print "\n[ OK ] 共读取 %s 行。" %len(col) new_col = [] new_col_tmp = [] ## 循环替换小写到大写;for循环两个参数时用zip包含 for f_old_str,f_new_str in zip(old_str,new_str): print "[ Info ] 正在查找 '%s' 并替换成 '%s'" %(f_old_str,f_new_str) if not new_col_tmp : ## 首次循环列表空,复制列表 new_col_tmp = col for col_list in new_col_tmp: new_col.append(col_list.replace(f_old_str,f_new_str)) ## 交换列表值,防止多次循环重复添加 ## 清空列表 new_col_tmp = [] ## 复制列表 new_col_tmp = new_col ## 清空列表 new_col = [] print "[ OK ] 共修改 %s 行。" %len(new_col_tmp) ## save date to EXCLE row = 0 #行 column = 9 # 列 ## 新建文件 #workbook1 = xlwt.Workbook() ## 打开文件追加(覆盖)原内容,formatting_info=True保留文件原来格式 #workbook1 = xlrd.open_workbook(r'/media/win-share-c/test.xls') workbook1 = xlrd.open_workbook( xls_list, formatting_info=True) #print workbook ## 新文件中添加,名字为"Style"的sheet页,内容cell_overwrite_ok覆盖 #sheet_wt = workbook.add_sheet('Style',cell_overwrite_ok=True) ## 将xlrd的对象转化为xlwt的对象 workbook = copy(workbook1) ## 获取要操作的第0个sheet页 sheet_wt = workbook.get_sheet(1) ## 循环追加写入内容 for i in range(len(new_col_tmp)): sheet_wt.write(row,column,new_col_tmp[i]) ## 到下一行 row = row + 1 ## 捕获保存文件异常 try: workbook.save( xls_list ) except IOError: print "\n[ Error ] 写入错误,请关闭文件!\n" else: def_xls_file_name = os.path.basename(xls_list) print "\n[ OK ] 文件: %(def_xls_file_name)s 第%(column)s列,小写转大写完成,保存到文件完成!\n" % locals(); return ## function Maindef main(): ## 查找.xls后缀文件 xls_file_lists = [] ## 循环查找py文件同目录及子目录下的xls文件 for filepath,dirnames,filenames in os.walk(os.getcwd()): for filename in filenames: ## 文件后缀为.xls,则添加到列表中 if os.path.splitext(filename)[1] == '.xls': ## sep自动识别系统路径分割,用'/'或'\' #xls_file_lists.append(os.path.join(filepath,filename)) xls_file_lists.append(os.sep.join([filepath,filename])) len_xls_file_lists = len(xls_file_lists) print "\n共找到 %s 个xls后缀文件:" %len_xls_file_lists ## 列出找到的xls后缀文件 for list in xls_file_lists: print list ## 开始读取数据并替换 for xls_list in xls_file_lists: print "\n开始读取: %s" %xls_list str_to_STR( xls_list ) if ( __name__ == '__main__' ) or ( __name__ == 'main' ): main();
效果图:
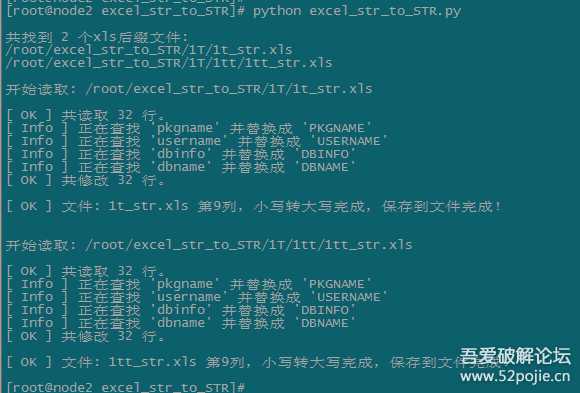
image.png
执行提示
替换前:

image.png
替换前
替换后:
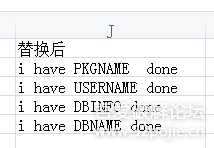
image.png
替换后
__EOF__
广告合作:本站广告合作请联系QQ:858582 申请时备注:广告合作(否则不回)
免责声明:本站资源来自互联网收集,仅供用于学习和交流,请遵循相关法律法规,本站一切资源不代表本站立场,如有侵权、后门、不妥请联系本站删除!
免责声明:本站资源来自互联网收集,仅供用于学习和交流,请遵循相关法律法规,本站一切资源不代表本站立场,如有侵权、后门、不妥请联系本站删除!
暂无评论...
更新日志
2024年11月25日
2024年11月25日
- 凤飞飞《我们的主题曲》飞跃制作[正版原抓WAV+CUE]
- 刘嘉亮《亮情歌2》[WAV+CUE][1G]
- 红馆40·谭咏麟《歌者恋歌浓情30年演唱会》3CD[低速原抓WAV+CUE][1.8G]
- 刘纬武《睡眠宝宝竖琴童谣 吉卜力工作室 白噪音安抚》[320K/MP3][193.25MB]
- 【轻音乐】曼托凡尼乐团《精选辑》2CD.1998[FLAC+CUE整轨]
- 邝美云《心中有爱》1989年香港DMIJP版1MTO东芝首版[WAV+CUE]
- 群星《情叹-发烧女声DSD》天籁女声发烧碟[WAV+CUE]
- 刘纬武《睡眠宝宝竖琴童谣 吉卜力工作室 白噪音安抚》[FLAC/分轨][748.03MB]
- 理想混蛋《Origin Sessions》[320K/MP3][37.47MB]
- 公馆青少年《我其实一点都不酷》[320K/MP3][78.78MB]
- 群星《情叹-发烧男声DSD》最值得珍藏的完美男声[WAV+CUE]
- 群星《国韵飘香·贵妃醉酒HQCD黑胶王》2CD[WAV]
- 卫兰《DAUGHTER》【低速原抓WAV+CUE】
- 公馆青少年《我其实一点都不酷》[FLAC/分轨][398.22MB]
- ZWEI《迟暮的花 (Explicit)》[320K/MP3][57.16MB]