**python 下载m3u8文件,将喜欢的视频存储到本地**
一、 获取真实的地址
书接上回,在经过三层解密之后,终于在开发者工具中将JS跑起来了
不知道咋回事的朋友可以看[https://www.52pojie.cn/thread-1725564-1-1.html](http://) 这一帖。
在每次重新发送请求的时候,有个请求的链接,映入我的眼帘,因为每次请求index.m3u8 文件失败后,就会出现这个链接以请求新的资源文件。
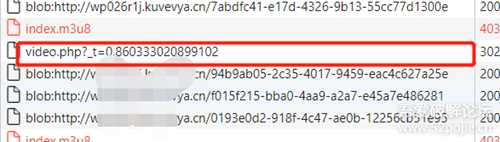
对的就是以video.php 开头的那个链接,后面的参数_t有没有觉得好面熟,是不是像个时间戳?双击链接直接打开
发现浏览器竟然直接将index.m3u8,下载下来了。汗:rggrg:rggrg:rggrg:rggrg:rggrg:rggrg(让我情何以堪,上一篇还过了三关才跑起来的JS)。
这里的API ,竟然直接不用任何JS就可以访问到了,想想就气,但是貌似如果不过三关,也发现不了这个API。
连续刷新了几次链接,发现每次都会下载一个新的m3u8文件,文件内容不一致,所以推断文件是随机下载的。
index*.m3u8 文件内容如下:

回到开发者工具的网络选项:
注意看下图中的 箭头指向
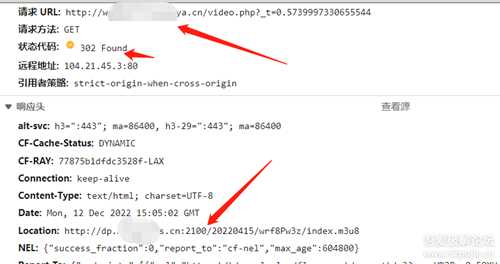
302 跳转了,注意上下两个地址发生了变化。
用上面的m3u8中地址加上跳转后的域名,拼接出来新的请求地址,请求后得到下面的内容:
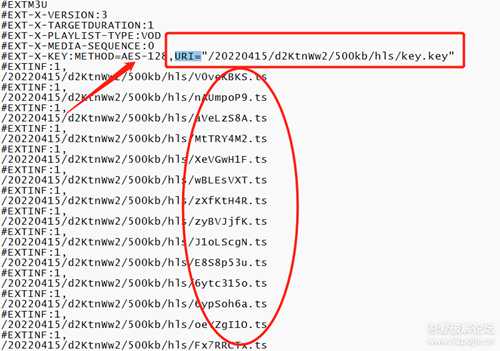
Ts的文件终于出现了,但是文件存在加密,但是不怕因为URI= 后面对应的就是key的地址啊。加密方式也写出来了 AES-128啊。
其实请求到真实的m3u8 地址之后,有牛人早就写出来工具了,直接填写真实地址下载即可:
分享github m3u8-downloader

并且大牛写的工具已经实现了自动AES-解密,还可以再油猴上面添加,直接嗅探页面的视频。

另外推荐一个工具就是youtube-dl 也是可以直接命令行 下载m3u8的并且能实现自动解密(不过要基于ffmpeg,需要下载ffmpeg,并将其所在的目录添加到环境变量)。
直接 pip install youtube-dl 安装即可。
二、 python 自动下载对应视频
既然流程已经搞清楚了,接下来就是用python 实现下载视频的时候了,但是再开始之前我们还是要确定一下 那个_t 参数是不是时间戳,直接开发者工具搜索 _t

找到了js实现 _t 参数的地方,Math.random() 的作用就是娶个大于零小于一的随机双浮点小数,奶奶的,分析完了发现不加应该也可以,起初还以为时间戳。
写程序最重要的是思路,而决定思路的就是上面一步步访问的流程,梳理如下:
1、 访问 domain+/video.php?_t=随机值 ,通过重定向url,获得第一层的m3u8文件内容。
2、 访问 重定向后的domian+ m3u8文件内容得到,真实的m3u8地址。
3. 自己编写Aes-128解密信息(或通过youtube-dl)实现下载。
其实把上面的思路理清楚了,程序自然就出来了,python 代码如下:
1、 访问上面的地址video.php地址一千次,得到一个列表(这些代码还是我一次爬取的时候写的那个,现在有个优化版的,所以下面的—t参数还是用的原来的时间戳形式)。
[Python] 纯文本查看 复制代码
# 模块导入import requestsimport time# 定义变量domain = "http://XXXXXXXX.cn/"search = "video.php?_t"now = time.time()# 定义函数def get_html(url): try: r = requests.get(url, timeout=30) with open("result.txt", "a") as f: f.write(r.text) f.close() r.close() print(r.text) except (ValueError): return "产生异常"# 主函数 for i in range(1, 1000): print("正在爬取第" + str(i + 1) + "页") time = "=0." + (str(now).replace('.', '')) get_html(domain + search + time)
经过我10几次实验,也就是访问了10000多次后,去除重复后发现仅剩余649个地址,也就基本探测出这个网站的小视频再650个左右。
2、 通过读取result.txt 去重后得到 剩余的不重复的地址:
[Python] 纯文本查看 复制代码
# 读取result.txt文件,并返回以/开始的行 不知道为什么这样写的可以看上面的 第一层m3u8 文件 因为前面两行都是以 # 开头的domain_301="XXXXX"def get_m3u8(): with open("result.txt", "r") as f: for line in f.readlines(): if line.startswith("/"): with open("m3u8.txt", "a") as file: file.write(domain_301 + line) file.close() f.close()
3. 去重复上面生成的 m3u8.txt
[Python] 纯文本查看 复制代码
# 读取m3u8.txt文件,并去除重复行def get_m3u8(): with open("m3u8.txt", "r") as f: lines = f.readlines() print(len(lines)) lines = list(set(lines)) print(len(lines)) f.close() with open("m3u8.txt", "w") as file: file.writelines(lines) file.close()
小分享:列表的set 函数可以去除重复的值哦,不记得的赶紧去复习!!!
4. 遍历新的文件,youtube-dl 下载
[Asm] 纯文本查看 复制代码
# 导入模块import osfrom multiprocessing.pool import ThreadPool# 定义变量save_path = 'D:\\video\\download\\movie\\'filetype = ".mp4 "oerder = "youtube-dl -o "# 读取m3u8.txt,并返回列表def get_m3u8(): with open("m3u8.txt", "r") as f: lines = f.readlines() print(len(lines)) f.close() return lines# 运行youtube-dl,下载视频def get_video(url): os.chdir(save_path) filename = url.split('/')[4] if os.path.exists(filename + filetype): print("文件已经存在") else: os.system(oerder + filename + filetype + url)# 线程函数def thread_task(lock, data_set): lock.acquire() get_video(data_set) lock.release()# 主函数if __name__ == '__main__': data_set = get_m3u8() with ThreadPool(10) as pool: pool.map(get_video, data_set, chunksize=1)
嘿嘿嘿,顺带写了一个多线程。
三、后记
其实后面优化了上面的程序,但是为了符合流程及一步步的写了代码,这样更便于像我一样的小白编写程序。顺带炫耀一下我的战利品!

哈哈哈,必须要码啊!!!
广告合作:本站广告合作请联系QQ:858582 申请时备注:广告合作(否则不回)
免责声明:本站资源来自互联网收集,仅供用于学习和交流,请遵循相关法律法规,本站一切资源不代表本站立场,如有侵权、后门、不妥请联系本站删除!
免责声明:本站资源来自互联网收集,仅供用于学习和交流,请遵循相关法律法规,本站一切资源不代表本站立场,如有侵权、后门、不妥请联系本站删除!
暂无评论...
更新日志
2024年12月23日
2024年12月23日
- 小骆驼-《草原狼2(蓝光CD)》[原抓WAV+CUE]
- 群星《欢迎来到我身边 电影原声专辑》[320K/MP3][105.02MB]
- 群星《欢迎来到我身边 电影原声专辑》[FLAC/分轨][480.9MB]
- 雷婷《梦里蓝天HQⅡ》 2023头版限量编号低速原抓[WAV+CUE][463M]
- 群星《2024好听新歌42》AI调整音效【WAV分轨】
- 王思雨-《思念陪着鸿雁飞》WAV
- 王思雨《喜马拉雅HQ》头版限量编号[WAV+CUE]
- 李健《无时无刻》[WAV+CUE][590M]
- 陈奕迅《酝酿》[WAV分轨][502M]
- 卓依婷《化蝶》2CD[WAV+CUE][1.1G]
- 群星《吉他王(黑胶CD)》[WAV+CUE]
- 齐秦《穿乐(穿越)》[WAV+CUE]
- 发烧珍品《数位CD音响测试-动向效果(九)》【WAV+CUE】
- 邝美云《邝美云精装歌集》[DSF][1.6G]
- 吕方《爱一回伤一回》[WAV+CUE][454M]